The cluster at GSI
GSI has a cluster located within the Green IT Cube.
It features
- A number of worker nodes a.k.a. execution nodes a.k.a. number crunchers
- A number of storage machines which constitute a
Lustrefile system, which is mounted on the worker nodes - A
SLURMinstance to manage computing workloads.
All of these machines are connected to an IPoverIB InfiniBand network with private IPs.
This cluster is meant to be serving multiple computing/storage use cases, for example for
- Current experiments at GSI
- Future experiments at GSI/FAIR
- Individual users at GSI/FAIR
- Short-lived or long-lived collaborations with remote institutions
There is typically no partitioning of the worker nodes by user/group/experiment. Which means anyone’s computing payload can be executed on any worker node.
In general, the network policy for the cluster machines’ network is:
- Nothing in
- Nothing out
The problem
However, some experiments, such as ALICE at CERN, have, for better or worse, designed their computing workflows in such way that the computing payload requires to connect to the outside world during runtime.
Since the collaboration with ALICE is too important to be subject to the cluster’s network policy, an exception needed to be implemented.
A solution needs to fulfil at least the following requirements
- The outgoing connections from ALICE computing payloads MUST be permitted
- Any outgoing connection from other processes MUST fall into the default routing workflow
- Outgoing connections MUST be NATed for internet-routability.
- The mechanism MUST be transparent for ALICE as well as for other users of the cluster
- The mechanism SHOULD be efficient
- The mechanism SHOULD be fault-tolerant
The solution
The following is an extremely simplified illustration of the default network situation around the cluster.
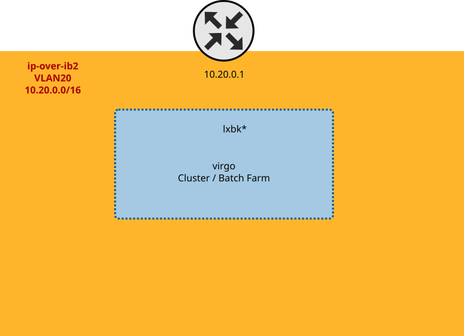
There is only one router, and it each worker node has configured it as its default gateway.
That router sends the packets it received to its default gateway, heading for the firewall, which drops packets attempting to connect to the outside.
The solution is a mechanism which consists of two parts.
Worker Node Configuration
On each worker node
- The connections made by the ALICE computing payload are marked (
iptablesterminology) by selecting by theUIDorGIDof the process - The
Linuxkernel gets instructed to use a different routing table for packets with that specific mark - The special routing table most importantly involves a different default gateway
Specifically, we configure a special routing table:
/etc/iproute2/rt_tables
#
# reserved values
#
255 local
254 main
253 default
0 unspec
#
# local
#
#1 inr.ruhep
201 alinatWe set the iptables marking mechanism as well as the ip rule mechanism in a systemd unit file.
/etc/systemd/system/route.service
[Unit]
Description=Routing Configuration
Requires=network-online.target
Wants=systemd-networkd-wait-online.service sssd.service
After=network-online.target sssd.service
[Service]
Type=oneshot
RemainAfterExit=true
ExecStart=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner aliprod -j MARK --set-mark 1
ExecStart=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner alise -j MARK --set-mark 1
ExecStart=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner rgrosso -j MARK --set-mark 1
ExecStart=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --gid-owner alice -j MARK --set-mark 1
ExecStart=/usr/sbin/iptables -t mangle -A OUTPUT -p tcp -m owner --uid-owner aliprod -j MARK --set-mark 1
ExecStart=/usr/sbin/iptables -t mangle -A OUTPUT -p tcp -m owner --uid-owner alise -j MARK --set-mark 1
ExecStart=/usr/sbin/iptables -t mangle -A OUTPUT -p tcp -m owner --uid-owner rgrosso -j MARK --set-mark 1
ExecStart=/usr/sbin/iptables -t mangle -A OUTPUT -p tcp -m owner --gid-owner alice -j MARK --set-mark 1
ExecStart=-/usr/sbin/ip rule del fwmark 1 table alinat
ExecStart=-/usr/sbin/ip r flush table alinat
ExecStart=/usr/sbin/ip rule add fwmark 1 table alinat
ExecStart=/usr/sbin/ip r add 10.20.0.0/16 dev ib0 table alinat
ExecStart=/usr/sbin/ip r add 10.20.1.0/24 dev ib0 table alinat
ExecStart=/usr/sbin/ip r add 10.10.24.0/24 via 10.20.0.1 dev ib0 table alinat
ExecStart=/usr/sbin/ip r add 140.181.2.0/24 via 10.20.0.1 dev ib0 table alinat
ExecStart=/usr/sbin/ip r add 140.181.60.0/24 via 10.20.0.1 dev ib0 table alinat
ExecStart=/usr/sbin/ip r add default via 10.20.3.227 dev ib0 table alinat
ExecStop=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner aliprod -j MARK --set-mark 1
ExecStop=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner alise -j MARK --set-mark 1
ExecStop=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --uid-owner rgrosso -j MARK --set-mark 1
ExecStop=-/usr/sbin/iptables -t mangle -D OUTPUT -p tcp -m owner --gid-owner alice -j MARK --set-mark 1
ExecStop=/usr/sbin/ip rule del fwmark 1 table alinat
ExecStop=/usr/sbin/ip r flush table alinat
[Install]
WantedBy=multi-user.targetYou can see that in the unit file above in the ExecStart lines, we first perform the actions of ExecStop there, but we allow them to fail without letting the unit fail by using systemd’s =- syntax.
Using that trick, the unit file gets the desirable property of idempotence, which means it can be executed any number of times and will always achieve the same desired state of the specified items.
Consequently,
- The unit does not fail it it gets
started orrestarted whileiptablesandipare already configured correctly - In case the configuration of
iptablesoripgets changed (for example if a network interface goes down and up again) and thesystemdunit does of course not notice it, arestartof the unit will recover the configuration ofiptablesandip.
NAT Router Configuration
The second part is a machine functioning as a router. Routers connect networks, so that machine needs to have at least 2 network interfaces. One in the network with the worker nodes, and one in a network with public IPs. In our case, that network is 140.181.2.0/24 and we call it brokernetz.
That machine must be configured to act as a router. From a Linux point of view, that means that IP forwarding needs to be enabled. It may be desirable to restrict it to the network interface combinations that you want to allow. In our case, we want to allow forwarding between the IPoverIB network on interface ib0 and the 10GbE interface eth9.
Specifically, we configure IP forwarding:
[root@alinat1 ~]# cat /etc/sysctl.d/10-alinat.conf
net.ipv4.ip_forward = 1And use nftables to define between which interfaces we want to route packets.
[root@alinat1 ~]# nft list ruleset
table inet table1 {
chain input {
type filter hook input priority filter; policy accept;
}
chain forward {
type filter hook forward priority filter; policy drop;
iifname "ib0" oifname "eth9" accept
iifname "eth9" oifname "ib0" accept
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table ip tablenat {
chain postrouting {
type nat hook postrouting priority srcnat; policy accept;
oifname "eth9" masquerade
}
chain prerouting {
type nat hook prerouting priority dstnat; policy accept;
}
}That way we have a special router which routes the packets originating from the ALICE payloads on the cluster headed for the internet.
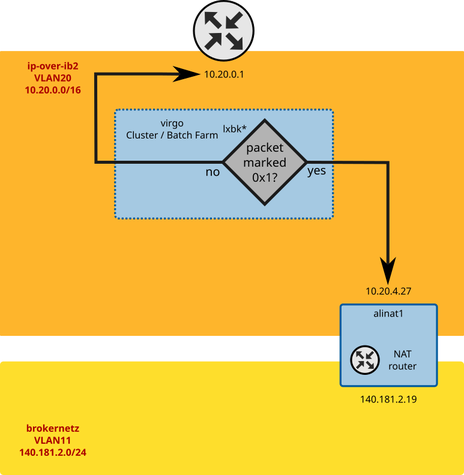
For ALICE we have several xrootd data servers which are dual-homed as well. They have an IPoverIB interface to be able to access Lustre, as well as a 10GbE interface in the brokernetz to be reachable from the Internet.
That happens to be just the network configuration of our NAT router.
To increase fault tolerance, we configured each of them to be a NAT router as well. However, only at most one of them is active at a given time. Under normal circumstances, that means exactly one machine plays the role of the NAT router.
For that we use keepalived. It is a daemon that utilizes the Virtual Router Redundancy Protocol (VRRP).
We configure keepalived on each of these machines to define a virtual router (keepalived terminology) with exactly one “virtual” IP address. Each keepalived daemon gets configured to have a specific priority. They then communicate with one another and figure out which one of the alive daemons has the highest priority. The one with the highest priority will claim the virtual IP, which is the IP configured on all worker nodes on the cluster.
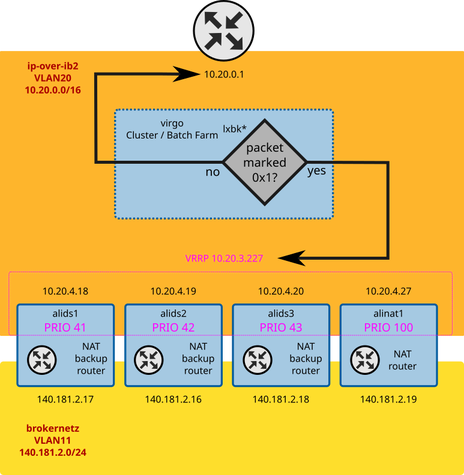
That way, even when the primary NAT router fails, the machine with the at that point in time highest priority will take over.
Any of the NAT routers can be rebooted or otherwise taken offline without resulting in any unavailability of the NAT mechanism as long as at least one of them is still operational.
Conclusion
This setup has proven to have an excellent specificity and sensitivity, which is to say there have not been any observed false positives or false negatives w.r.t. which packets get routed to our NAT router vs the normal default gateway.
Secondly, it is extremely efficient. Even when saturating the 10GbE link there is hardly any noticable CPU usage on the NAT router.
Also, it is reliable and probably the most fault-tolerant component in our ALICE setup.
There is slight operational room for improvement on the worker node side. In case the InfiniBand network goes down and up again, the IP address disappears and all routes with it. Currently we do not automatically recover from that fault, but we detect it and manually need to restart route.service. This could theoretically be further automated.